

PerMMLU

MMLU چیست؟
MMLU (اختصار Massive Multitask Language Understanding) یک بنچمارک جامع برای سنجش درک زبانی مدلهای زبانی بزرگ (LLMs) است که توسط دانشگاه UC Berkeley توسعه داده شده است. این بنچمارک شامل بیش از ۱۵ هزار سوال چندگزینهای در ۵۷ حوزهی دانشی مختلف است که از منابع مختلفی چون امتحانات دانشگاهی، آزمونهای حرفهای، و اطلاعات عمومی گردآوری شدهاند. هدف اصلی MMLU ارزیابی توانایی مدلهای زبان در پاسخگویی به سوالات سطح بالا و میانرشتهای است.
سوالات MMLU از حوزههایی چون علوم انسانی (تاریخ، فلسفه، ادبیات)، علوم پایه (فیزیک، شیمی، ریاضی)، علوم اجتماعی (جامعهشناسی، روانشناسی)، پزشکی، حقوق، کسبوکار، و تکنولوژی تشکیل شدهاند. این تنوع موضوعی به ارزیابان اجازه میدهد تا عملکرد مدلها را نهتنها در تولید زبان طبیعی، بلکه در میزان عمق و صحت دانش آنها نیز بسنجند. ویژگی خاص این مجموعه، آن است که سوالها همگی استاندارد و مشابه آزمونهای واقعی هستند.
MMLU به سرعت به یک معیار پذیرفتهشده برای سنجش مدلهای بزرگ مانند GPT، LLaMA، PaLM و دیگر LLMها تبدیل شده است. نتایج آزمونهای MMLU معمولاً در مقالات و ارائههای رسمی مدلها منتشر میشود و به عنوان یکی از چالشهای اصلی در هوش مصنوعی عمومی شناخته میشود.
PersianMMLU (Khayyam Challenge)

با توجه به اهمیت MMLU در سطح جهانی، پژوهشگران ایرانی تلاش کردند تا نسخهای از این بنچمارک را برای زبان فارسی توسعه دهند. نتیجهی این تلاش، مجموعه دادهای به نام PersianMMLU یا چالش خیام بود. این مجموعه شامل ۲۰٬۱۹۲ سوال چندگزینهای برگرفته از آزمونهای رسمی مدارس ایران در پایههای مختلف تحصیلی و در ۳۸ موضوع متنوع است، که موضوعاتی چون درک ادبی، ریاضی، علوم، منطق، و آزمونهای هوش را در بر میگیرد. هدف این چالش، ارزیابی دقیق مدلهای زبانی فارسی در ابعاد مختلفی همچون فهم زبان و استدلال بوده است.

با وجود ارزشمند بودن، بنچمارک PersianMMLU ، این بنچمارک دارای محدودیتهایی است. نخست آنکه دامنهی سوالات آن محدود به موضوعات تدریسشده در مقطع مدرسه است و اغلب حوزههای دانشگاهی، تخصصی یا فرهنگی مانند قوانین ایرانی، طب سنتی، مشاهیر ایرانی، مسائل پزشکی، مسائل فنی مهندسی و دانش مختص به جامعه ایرانی را پوشش نمیدهد. دوم اینکه تنوع زبانی و سبک نگارش سوالات در آن کم بوده و بیشتر بر آموزش رسمی و استاندارد مدارس متکی است، که میتواند باعث عدم پوشش کامل مهارتهای زبانی مدلها شود.
همچنین، این مجموعه بهطور کامل از دیدگاه بینرشتهای بودن یا تحلیلهای سطح بالا که در نسخه اصلی MMLU وجود دارد، فاصله دارد. با وجود تلاش برای پرهیز از مشکلات آلودگی داده و استفاده از دادههای اصیل و بومی برای فارسیزبانان، همچنان برای ارزیابی جامع و دقیق مدلهای زبانی فارسی، نیاز به یک بنچمارک گستردهتر، متنوعتر و مقیاسپذیر احساس میشود.
معرفی PerMMLU – گامی نوین در ارزیابی جامع زبان فارسی
PerMMLU جهت رفع محدودیت های موجود درPersianMMLU، توسعه داده شده است. در ساخت این بنچمارک تلاش شده تا یک بنچمارک جامعتر، متنوعتر و تطبیقپذیر با ویژگیهای زبانی و فرهنگی ایرانیان ایجاد شود. این بنچمارک با هدف پوشش سه بعد مهم از دانش فارسی طراحی شده و در قالب سه مجموعه دادهی مستقل و مکمل ارائه میشود: UPK ، SPK و GPK
نخستین بخش، SPK (School Persian Knowledge)، شامل ۵۵۸۱ سوال چهارگزینهای از دروس رسمی مدارس ایران است که از پایه چهارم تا دوازدهم و در ۷۸ موضوع متنوع میباشد. این مجموعه داده از وبسایت آموزشی پادرس کرال شده است و سپس توسط انسان و مدل های زبانی بزرگ(LLMs) تمیز سازی شده تا سوالاتی که ناقص هستند یا نیاز به اطلاعات اضافی همچون تصویر، نمودار یا جدول دارند، حذف شوند. این دیتاست پایهای منسجم برای ارزیابی توانایی مدلها، در فهم محتوای درسی مدارس به زبان فارسی ایجاد میکند.
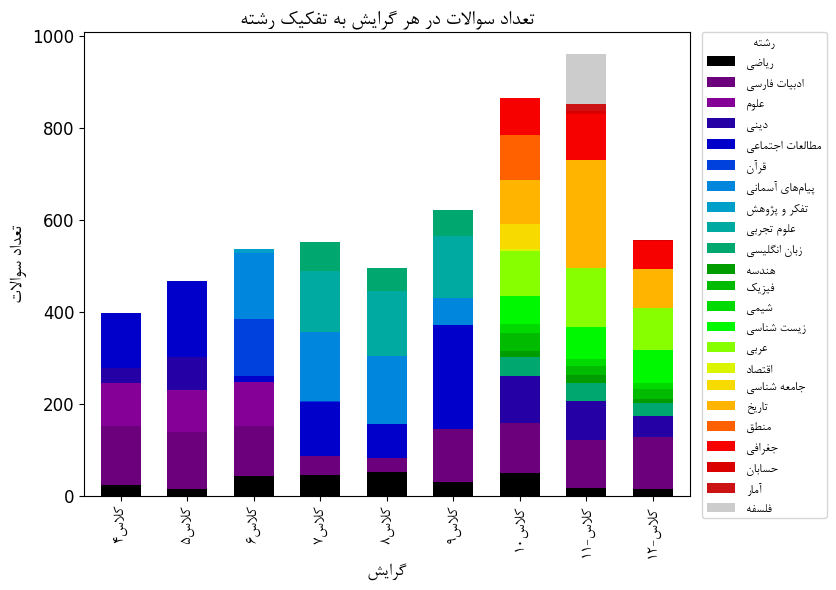
مثال از دیتاست SPK:
نمونه سوال - دستهبندی: تاریخ دهم
سؤال: در کدام کشور باستانی، مجموعه متون دینی (وداها) در حدود 1200 ق م به صورت مکتوب در آمد؟
گزینهها: ۱) هند ۲) چین ۳) یونان ۴) میان دورود
پاسخ صحیح: ۱) هند
دومین مجموعه، UPK (University Persian Knowledge)، شامل ۷۷۹۳ سوال و جواب چهارگزینهای برگرفته از آزمونهای کنکور کارشناسی ارشد و دکترا در ۲۵ رشته دانشگاهی است که حوزههایی مانند پزشکی، مهندسی، علوم انسانی و هنر را پوشش میدهد. این مجموعه تلاش میکند خلأ موجود در چالش خیام را با ارائهی متونی تخصصی و سطحبالای علمی جبران کند و مدلهای زبانی را در مواجهه با مفاهیم دانشگاهی به چالش بکشد. در فرآیند گردآوری این دادهها، از فناوری OCR برای استخراج سوالات و پاسخها از دفترچه کنکورهای ارشد و دکترا استفاده شده و از مدلهای زبانی بزرگ (LLM) برای پاکسازی و تمیزسازی دادهها بهره گرفته شده است. طراحی این مجموعه بهگونهای بوده که پوشش جامعی از مفاهیم تدریسشده در دانشگاه ارائه دهد و در مواردی که رشتهها اشتراک محتوایی بالایی داشتهاند، تنها یکی بهعنوان نماینده انتخاب شده است.
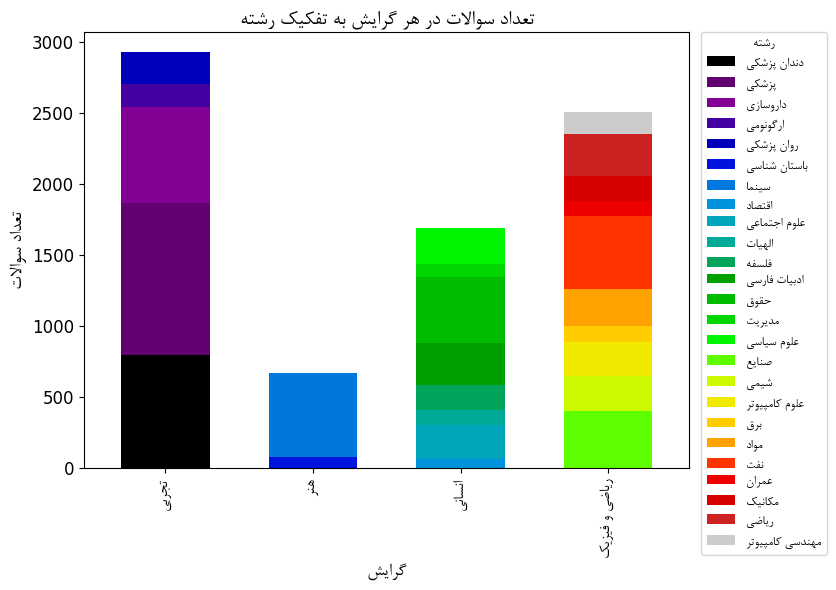
مثال از دیتاست UPK:
نمونه سوال - دستهبندی: عمران
سؤال: اگر ضخامت یک پی صلب ۸۰ سانتیمتر و پوشش بتن روی آرماتورهای آن ۱۰ سانتیمتر باشد، برای یک ستون مربعی به عرض ۵۰ سانتیمتر، مقطع بحرانی برای کنترل برش یکطرفه چند سانتیمتر از بر ستون فاصله دارد؟
گزینهها: ۱) ۷۰ ۲) ۶۲ ۳) ۴۰ ۴) ۳۵
پاسخ صحیح: ۱) ۷۰
در نهایت، GPK (General Persian Knowledge) با هدف ارزیابی دانش عمومی مدلها از موضوعاتی طراحی شده که مختص جامعه ایرانی هستند. منظور از دانش عمومی مختص جامعه ایرانی، دانشی است که در بستر فرهنگی، اجتماعی و قانونی ایران معنا و کاربرد دارد و برای آنکه مدلهای زبانی بزرگ با فرهنگ فارسی آشنا باشند، لازم است به این نوع دانش نیز تسلط داشته باشند. این مجموعه شامل ۱۰۰۳ سوال چهارگزینهای در ۱۵ موضوع مختلف است که زمینههایی مانند سوغات شهرها، احکام دینی، قوانین ملی، شخصیتهای مشهور، اصطلاحات فرهنگی و دیگر موضوعات بومی ایران را در بر میگیرد. این دادهها با جمعآوری اطلاعات از وبسایتهای مختلف و تولید ساختارمند سوالات از طریق پرامپتهای ویژه برای هر موضوع بهطور جداگانه توسط مدلهای زبانی بزرگ ساخته شدهاند. همچنین، دادههای حساستری مانند محتوای دینی و سیاسی توسط انسان بررسی و ویرایش شدهاند تا از بروز خطا یا سوگیری جلوگیری شود.
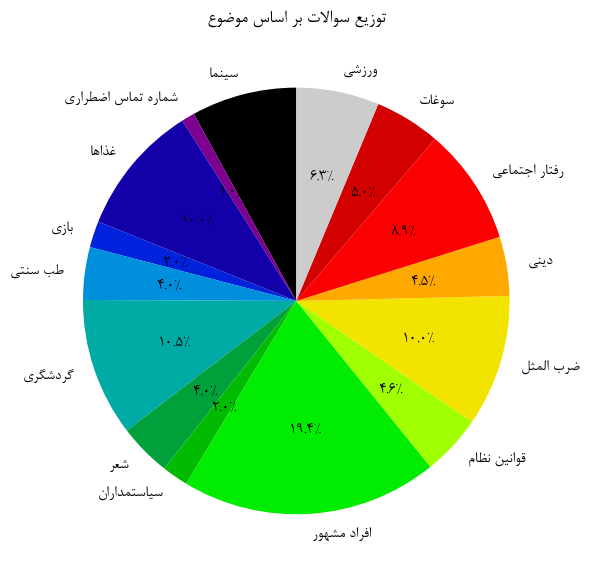
مثال از دیتاست GPK:
سؤال: ورزش کبدی مدرن از کدام بازی قدیمی برگرفته شده است؟
گزینهها: ۱) لوچو ۲) زو ۳) چوگو ۴) گورش
پاسخ صحیح: ۲) زو
PerMMLU با این رویکرد سهگانه، گامی مهم در مسیر ارزیابی دقیقتر و بومیتر مدلهای زبانی فارسی برداشته است.
مطلبی دیگر از این انتشارات
PerCoR
مطلبی دیگر از این انتشارات
MIZAN: A Persian LLM Leaderboard
مطلبی دیگر از این انتشارات
Persian MT-Bench