

MIZAN: A Persian LLM Leaderboard

مقدمه
تواناییها و کارایی مدلهای زبانی بزرگ(LLMs)، با استفاده از بنچمارکها یا آزمونهای استاندارد طراحی شده در وظایف گوناگون زبانشناختی، ارزیابی میشوند. این بنچمارکها ابعاد متعددی از عملکرد مدلها نظیر درک زبان طبیعی، قدرت استدلال، توانایی تولید متون، و پیروی از دستورالعملها را میسنجند. هر یک از این آزمونها با ارائه مجموعهای از سوالات چالشبرانگیز، تصویری جامع از نقاط قوت و ضعف مدلها ارائه میکنند.
جنبههای اصلی ارزیابی مدلهای زبانی
درک زبان طبیعی(NLU)
درک زبان طبیعی به معنای توانایی مدل در فهم، تفسیر و تحلیل متون انسانی است. این شامل درک معنای جملات، شناسایی موجودیتها، تشخیص احساسات و پاسخ به سوالات بر اساس متن است. آزمونهایی مانندGLUE و SQuAD برای ارزیابی این مهارت بهکار میروند.
تولید زبان طبیعی(NLG)
تولید زبان طبیعی به توانایی مدل در تولید متنهایی معنادار، روان و مرتبط با زمینه اشاره دارد. این توانایی شامل وظایفی مانند خلاصهسازی، ترجمه، پاسخگویی به سوالات و تولید خلاقانه متن میشود.
استدلال(Reasoning & Problem Solving)
استدلال، توانایی مدل در حل مسائل منطقی، ریاضی و مفهومی را میسنجد. بنچمارکهایی مانندCSQA، GSM8K، HellaSwag، AR-LSAT وReClor جنبههای مختلف استدلال رایج، ریاضی و استنتاجی را ارزیابی میکنند.
پیروی از دستورالعملها(Instruction Following)
سنجش توانایی مدل در دنبالکردن دستورات صریح و ضمنی، با استفاده از مجموعه دادههایی مانندIFEval وSuper-NaturalInstructions.
بنچمارکهای عمومی(General Purpose Benchmark)
بنچمارکهای عمومی برای ارزیابی توانایی کلی مدل در انجام طیف وسیعی از وظایف زبانی و دانشی طراحی شدهاند. این بنچمارکها شامل سوالاتی از حوزههای مختلف مانند تاریخ، پزشکی، حقوق، ریاضیات و علوم انسانی هستند و میزان دانش عمومی و تخصصی مدل را میسنجند. مجموعههایی مانندMMLU و ARC از جمله معیارهای استاندارد در این زمینه به شمار میروند.
چندزبانی(Multilinguality)
در این دسته، توانایی مدل در فهم و تولید متن به زبانهای مختلف مورد آزمایش قرار میگیرد. بنچمارکهایی مانندXGLUE وXTREME عملکرد مدل را در زبانهای گوناگون میسنجند.
قابلیت اعتماد و اخلاق (Robustness / Ethics / Biases / Trustworthiness)
این دسته به ارزیابی جنبههایی مانند ایمنی، بیطرفی، دقت و پایداری مدل در تعامل با انسانها میپردازد.
- Robustness : میزان مقاومت مدل در برابر ورودیهای گمراهکننده یا مخرب که ممکن است باعث پاسخهای نادرست شود.
- Ethics : توانایی مدل در پرهیز از تولید محتوای آسیبزا، تبعیضآمیز یا نامناسب.
- Biases : میزان تلاش مدل برای کاهش بازتولید سوگیریهای جنسیتی، قومی، فرهنگی یا زبانی.
- Trustworthiness: توانایی مدل در ارائه پاسخهای درست، دقیق و قابل اتکا در شرایط گوناگون.
Open LLM Leaderboard

Open LLM Leaderboard یک پلتفرم جامع و متنباز برای مقایسه و سنجش مدلهای زبانی بزرگ است که توسطHugging Face ارائه شده است. این پلتفرم با استفاده از چارچوب EleutherAI LM Evaluation Harness و دیگر ابزارهای ارزیابی، مدلها را در برابر مجموعهای از بنچمارکهای استاندارد و متنوع بررسی میکند.
در نسخه جدید، این پلتفرم عملکرد مدلهای LLM را روی مجموعهای از تسکهای بهروز و پیشرفته ارزیابی میکند که شامل موارد زیر است:
- IFEval: توانایی مدل را در پیروی دقیق از دستورالعملها، بهویژه در قالببندی و تولید متن مطابق با فرمت خواستهشده ارزیابی میکند.
- BBH (Big Bench Hard): مجموعهای از وظایف دشوار برای مدلهای زبانی بزرگ است که توانایی آنها را در فهم زبان، استدلال ریاضی، و دانش عمومی میسنجد.
- MATH: شامل مسائل پیچیده ریاضی در سطح دبیرستان است و مهارت مدل را در جبر پیشرفته، هندسه و حساب دیفرانسیل و انتگرال ارزیابی میکند.
- GSM8K-Pro یا (GPKA): این ارزیابی شامل سوالات چندگزینهای در سطح دکترای علوم است و دانش مدل را در زمینههای شیمی، زیستشناسی و فیزیک میسنجد.
- MUSR: این ارزیابی توانایی مدل را در درک زبان، استدلال، و تحلیل متون بلند مورد سنجش قرار میدهد.
- MMLU-Pro: نسخه تقویتشدهی MMLU شامل سوالات چندگزینهای با بازبینی تخصصی در حوزههای مختلف مانند پزشکی، حقوق، مهندسی و ریاضیات است و دقت و دانش مدل در این زمینهها را میسنجد.
- CO2: میزان انتشار CO₂ هنگام اجرای مدل را نشان میدهد و برای مقایسهی تأثیر زیستمحیطی مدلها در شرایط یکسان به کار میرود.
این تسکها جنبههای مختلفی از عملکرد مدلها را در زمینههایی مانند استدلال، دانش عمومی، پیروی از دستورالعملها، و حل مسائل چندمرحلهای پوشش میدهند.
MIZAN: A Persian LLM Leaderboard
لیدربورد میزان (MIZAN) با هدف ایجاد یک میزان و مرجع استاندارد برای ارزیابی مدلهای زبانی بزرگ(LLMs) در زبان فارسی توسعه یافته است. این لیدربورد بهگونهای طراحی شده که عملکرد مدلها را در طیف گستردهای از وظایف شامل دانش عمومی، استدلال منطقی و مهارتهای زبانی بهصورت چندبعدی مورد سنجش قرار دهد.
لیدربورد میزان در این آدرس در دسترس است.
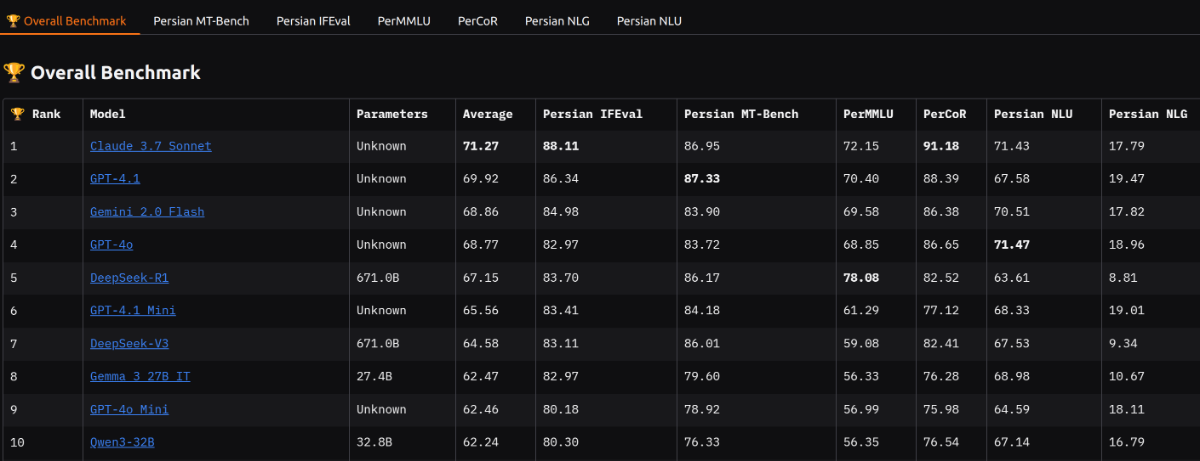
MIZAN: شامل شش بنچمارک اصلی است که هر یک بُعدی خاص از عملکرد مدلها را میسنجد:
۱. دانش عمومی استدلالی فارسی(PerCoR)
PerCoR مخفف "Persian CommonSense Reasoning" است و اولین بنچمارک بزرگمقیاس فارسی برای ارزیابی توانایی مدلها در استدلال دانش عمومی به صورت تکمیل جمله با چند گزینه است. این مجموعه شامل ۱۰۶هزار نمونه از حوزههای متنوعی مانند اخبار، دین، تکنولوژی و سبک زندگی است که از بیش از ۴۰ وبسایت فارسی استخراج شدهاند.
برای ساخت نمونهها از روشی نوآورانه بر اساس «تقسیمبندی با کلمات ربط» استفاده شده تا جملات و گزینهها هماهنگ و متنوع باشند. همچنین با روش جدید و نوآورانه DRESS-AF، که یک تکنیک بدون نیاز به تولید متن و مستقل از زبان است، گزینههای گمراهکننده، چالشبرانگیز و قابلحل برای انسان، ایجاد شدهاند.
برای مثال کدام گزینه ادامه منطقی جملهی زیر میباشد:

در این سوال تنها گزینه ۲ میتواند جواب منطقی برای جمله باشد. گزینه ۱ و ۳ در مورد موضوع دیگری صحبت میکنند و در گزینه ۴ زمان جمله با جمله اول تطبیق ندارد.
جزئیات بیشتر در مورد این بنچمارک را در این لینک میتوانید بخوانید.
۲. ارزیابی پیروی دستورالعمل فارسی(Persian IFEval)
این دیتاست نسخه فارسیشده و بومیشدهی IFEval است و توانایی مدلها در پیروی دستورالعملهای پیچیده را ارزیابی میکند. ترجمه بهصورت ترکیبی از ماشین و بازبینی انسانی انجام شده و پرامپتهای نامناسب برای زبان فارسی بازنویسی یا حذف شدهاند.
نمونهای از دستورالعمل در این دیتاست:
تویییتی برای وزیر خارجه ایران بنویسید. توییت باید شامل کلمات کلیدی "تحریم" و "برجام" باشد.
در این مثال، در دستورالعمل خواسته شده که دو کلمه کلیدی ('تحریم' و 'برجام') در متن خروجی موجود باشند. مدل باید توانایی تشخیص این کلمات کلیدی و گنجاندن آنها در خروجی را داشته باشد. این نوع تستها برای بررسی دقت مدل در اجرای دستورالعملهای پیچیده طراحی شدهاند.
۳. دانش عمومی و تخصصی فارسی (PerMMLU)
این بنچمارک نسخه فارسی و توسعهیافتهای از بنچمارک MMLU برای سنجش دانش عمومی و تخصصی مدلها میباشد. این دیتاست به نحوی توسعه داده شده تا علاوه بر علوم تدریس شده در مدارس، علوم دانشگاهی و دانش مختص فارسی زبانان را شامل شود. این مجموعه شامل:
- سوالات مدرسهای (پایه چهارم تا دوازدهم)
- سوالات دانشگاهی در رشتههای مختلف
- دانش عمومی مرتبط با فرهنگ و جامعه ایران (مانند قوانین، مشاهیر، سوغات)
می باشد.
جزئیات بیشتر در مورد این بنچمارک را در این لینک میتوانید بخوانید.
۴. بنچمارک چند نوبتی فارسی(Persian MT-Bench)
دیتاست Persian MT-Bench نسخهی بومیسازیشدهی مجموعهی MT-Bench به زبان فارسی است که با تغییرات محتوایی و ساختاری همراه بوده است. MT-Bench یک مجموعهی ارزیابی مبتنی بر پرسشوپاسخ چندنوبتی (multi-turn) و دیالوگمحور است که شامل ۸۰ گفتوگو در قالب ۲ نوبت (turn) و در ۸ موضوع مختلف میباشد.
در نسخهی فارسی، تمام نمونهها بهصورت دقیق ترجمه و سپس توسط انسان بازنویسی شدهاند تا از لحاظ زبانی و فرهنگی با کاربران فارسیزبان سازگار باشند. همچنین برای سنجش بهتر عملکرد مدلها در مکالمات بلند، برخی از نمونهها به ۳ یا ۴ نوبت مکالمه گسترش یافتهاند.
افزون بر این، دو موضوع جدید به مجموعه اضافه شده است، که هر یک شامل ۱۰ نمونه هستند:
- دانش بومی ایرانی: شامل سوالاتی دربارهی موضوعات فرهنگی مانند فیلمها، سوغات شهرها و چهرههای ایرانی.
- توانایی تولید در سیستم RAG (Chatbot-RAG): در این بنچمارک هر یک از سوالات به همراه چند سوال و پاسخ مرتبط از یک FAQ آمده است و مدل LLM باید با توجه به این سوال و پاسخهای مرتبط جواب سوال اصلی را بدهد و به این ترتیب قابلیت مدل در تولید متون در یک سیستم RAG ارزیابی میشود.
این گسترشها با هدف افزایش تنوع موضوعی و عمق ارزیابی مدلهای فارسیزبان انجام شدهاند. در نهایت بنچمارک Persian MT-Bench شامل ۱۰۰ گفتگو در قالب چند نوبتی(۲، ۳ یا ۴) و در ۱۰ موضوع مختلف میباشد.
برای ارزیابی جوابهای مدل روی این بنچمارک از روش قضاوت مدلهای بزرگ (LLM as a judge) استفاده شده است.
نمونه ای از داده چند نوبتی این دیتاست:
🔁 Turn 1 – کاربر:
نام چند فیلم و سریال ایرانی در زیر آورده شده است. تو نام کارگردانهای آنها را به ترتیب در خروجی در یک خط تولید کن.
نهنگ عنبر - آژانس شیشهای - یاغی - همیشه پای یک زن در میان است - هامون - دینامیت - شبهای برره - حوالی پاییز - نجلا - جیران
✅ پاسخ:
سامان مقدم - ابراهیم حاتمیکیا - محمد کارت - کمال تبریزی - داریوش مهرجویی - مسعود اطیابی - مهران مدیری - حسین نمازی - خیرالله تقیانی پور - حسن فتحی
🔁 Turn 2 – کاربر:
از هر یک از فیلم و سریالهایی که در سوال قبل گفته شد، نام یک شخصیت به ترتیب در زیر آمده است. نام بازیگران این نقشها را به ترتیب در خروجی در یک خط تولید کن.
ارژنگ صنوبر - حاج کاظم - طلا - امید - مهشید سلیمانی - اکبر فخار - لیلون - مهران - عدنان - کفایتخاتون
✅ پاسخ:
رضا عطاران - پرویز پرستویی - طناز طباطبایی - حبیب رضایی - بیتا فرهی - محسن کیایی - بهنوش بختیاری - حسین مهری - هدایت هاشمی - رؤیا تیموریان
🔁 Turn 3 – کاربر:
از بین فیلم و سریالهای گفته شده در سوال اول، قدیمیترین و جدیدترین فیلم سینمایی را به همراه سال انتشار مشخص کنید.
✅ پاسخ:
قدیمیترین فیلم سینمایی: هامون (1368)
جدیدترین فیلم سینمایی: دینامیت (1400)
جزئیات بیشتر در مورد این بنچمارک را در این لینک میتوانید بخوانید.
۵. درک زبان طبیعی فارسی (Persian NLU)
شامل مجموعهای از دیتاستهای موجود در فارسی برای ارزیابی درک زبان طبیعی است. این مجموعه مسائلی نظیر موارد زیر را شامل میشود:
- Text Classification: Synthetic Persian Tone, SID
- Natural Language Inference (NLI): FarsTAIL
- Semantic Textual Similarity (STS): Synthetic Persian STS, FarSICK
- Named Entity Recognition (NER): Arman
- Paraphrase Detection: FarsiParaphraseDetection, ParsiNLU
- Extractive Question Answering (EQA): PQuAD
- Keyword Extraction: Synthetic Persian Keywords
- Sentiment Analysis: DeepSentiPers
هر کدام از این مسائل جنبه خاصی از LLMها را در درک زبان طبیعی فارسی ارزیابی میکند. برای مثال شما اگر میخواهید، قابلیت استخراج کلمات کلیدی را در LLMها بسنجید کافیست به ستون دادگان Keyword Extraction مراجعه کنید.
۶. تولید زبان طبیعی فارسی(Persian NLG)
این بخش مربوط به تولید زبان طبیعی است و تسکهایی نظیر:
- Summarization: SamSUM-fa, PnSummary
- Machine Translation: TEP, MIZAN, EPOQUE, ...
- Question Generation: PersianQA
را در بر میگیرد. هدف این ارزیابی بررسی قابلیت تولیدی مدلهاست.
این مسائل نیز قابلیت مدلها را از جنبههای مختلف برای تولید متن مورد ارزیابی قرار میدهند. برای بررسی توانایی مدلها در خلاصه سازی متن، میتوان ستون دادگان خلاصه سازی را بررسی کرد. همچنین برای ارزیابی دقت مدل ها در ترجمه متن در سه زبان فارسی، انگلیسی و عربی می توان ستون مربوط به دادگان ترجمه را بررسی کرد.
نتیجهگیری
لیدربورد ارزیابی مدلهای زبانی بزرگ در فارسی (MIZAN) گامی مؤثر برای سنجش توانایی مدلهای زبانی در زبان فارسی است و میتواند به عنوان میزان و مرجع ارزیابی برای پژوهشگران و توسعهدهندگان باشد.
لینک ها
لیدربورد میزان:
https://huggingface.co/spaces/MCINext/mizan-llm-leaderboard
دیتاستهای بنچمارکها:
https://huggingface.co/datasets/MCINext/persian-nlg
https://huggingface.co/datasets/MCINext/persian-nlu
https://huggingface.co/datasets/MCINext/persian-mt-bench
PerMMLU
PerCoR
Persian MT-Bench